Deux cas documentés en avril-mai 2026 : un confrère freelance qui republie mes articles vingt-quatre heures après ma publication, une content farm qui pille à la chaîne 30 articles vérifiés sur 70 correspondances. Mécanique du pillage SEO assisté par IA, signatures techniques d’automation, et grille pratique pour détecter, tracer et vous défendre.
Le 10 mai 2026, je remonte les logs d’accès de mon serveur. Une requête répétée attire l’oeil : un visiteur charge une de mes images directement depuis un domaine que je ne connais pas. Brandeclic.com. Je tape l’URL pour voir et… bingo. L’article servi en face est un de mes contenus, réécrit à peu près, illustré par mon image, sans aucun lien retour vers wpformation.
Je creuse. 30 articles plagiés vérifiés, 70 correspondances probables sur 143 publications, une seule ferme de contenu. Et pendant que je remonte cette piste, je me souviens d’un autre cas plus discret, croisé deux semaines plus tôt. Un freelance React/Next.js qui republie mes articles dans la fenêtre 0-24 heures après ma publication, en gardant exactement ma sélection éditoriale et ma nomenclature, avec une plume LLM qui lisse l’ensemble.
Deux échelles, une seule mécanique. Mécanique. Brutale. Reproductible. Je raconte ici comment ça fonctionne, pourquoi ça pourrit le métier, et surtout comment vous en défendre quand ça vous tombe dessus.
Comment fonctionne un plagiat WordPress assisté par IA ?
Le pillage SEO assisté par IA ne ressemble plus au plagiat de nos vingt ans. Personne ne copie-colle de paragraphes. Si vous passez un de mes articles dans Copyscape contre une copie suspecte, vous trouvez peu de chose. La fraude est plus subtile, et à mes yeux plus dommageable.
Pourquoi ça marche aussi bien ? Parce que le process tient en cinq phases bien rodées, dont la combinaison neutralise tous les détecteurs classiques.
- Repérage. Veille manuelle, flux RSS, suivi LinkedIn d’auteurs prolifiques, ou simple script qui surveille les sitemaps de quelques sites de référence. Capter le contenu fraîchement publié sur des mots-clés à valeur SEO.
- Extraction de la structure éditoriale. Le voleur ne récupère pas le texte. Il récupère ce qui a coûté à l’auteur : l’angle choisi, les sources sélectionnées, les exemples, les chiffres, l’enchaînement des arguments. Le vrai travail.
- Réécriture LLM. Un prompt du type "réécris en gardant les mêmes idées et les mêmes sources, change la formulation". Le résultat passe les détecteurs de plagiat textuel mais reproduit la valeur intellectuelle du document source.
- Publication accélérée. Souvent dans la fenêtre 24 heures qui suit l’article original. Exister sur Google avant que la source ne consolide son ranking.
- Aucun lien sortant. Logique : le but n’est pas d’enrichir le lecteur, c’est de capter le trafic qu’il aurait adressé à la source.
Le coût marginal d’un article ainsi pillé est dérisoire. Quelques centimes d’API LLM, dix minutes de scraping, une publication automatique. La marge unitaire est mécaniquement énorme dès que l’article ranke un peu… et c’est exactement ça qui rend le modèle viable à grande échelle.
Le coût pour la victime, lui, est triple. Vous travaillez gratuitement pour quelqu’un d’autre. Vous perdez du trafic SEO sur des mots-clés que vous avez établis. Vous contribuez malgré vous à la dégradation des résultats Google. Et le coût pour le lecteur est qu’il consomme un texte appauvri, sans accès aux sources originales qui auraient dû l’enrichir.
Deux cas documentés en avril-mai 2026
Ce qui sépare ces deux cas n’est pas la nature du pillage. C’est son échelle. L’un commence, l’autre est déjà industrialisé. La même mécanique, deux degrés de maturité.
Le pattern à 24 heures : Jeremy Teurterie
Jeremy Teurterie est développeur React et Next.js basé en France. Profil LinkedIn actif, prestations de freelance SEO. Sur le papier, un confrère.
Trois reprises documentées sur jeremyteurterie.com, en l’espace d’un mois. Trois articles. Trois sujets sur lesquels j’ai publié en avril 2026. Trois articles qui réapparaissent côté Jeremy, sous une plume différente mais avec la même ossature.
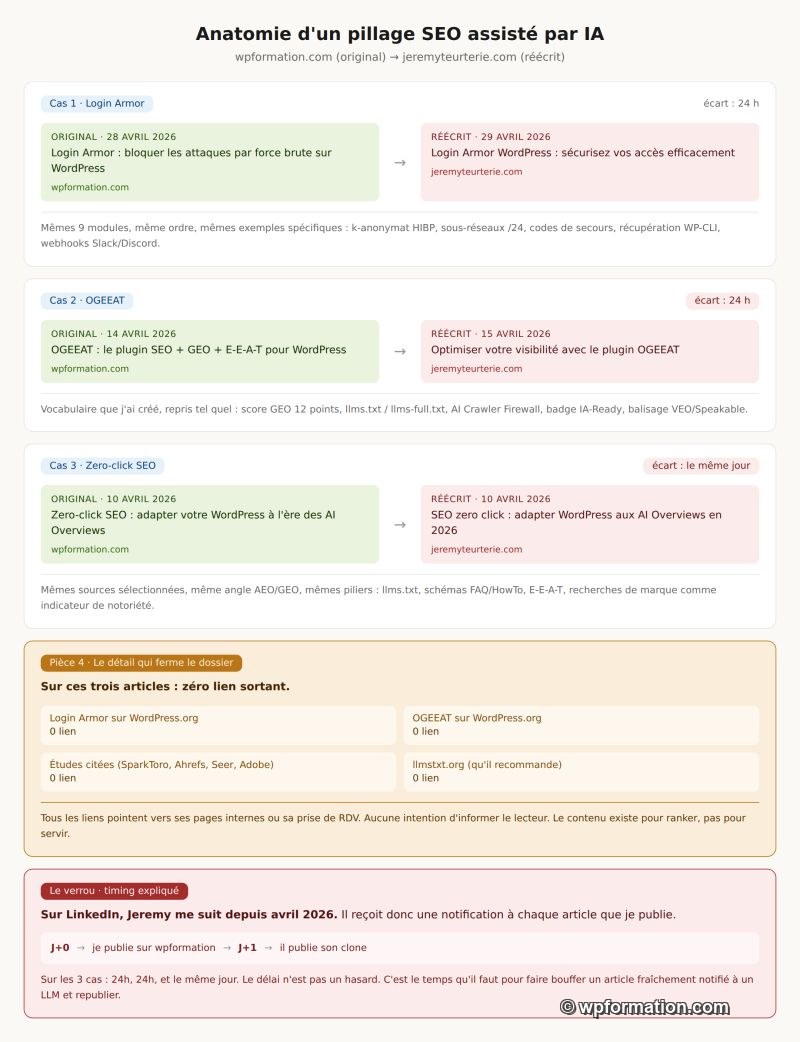
- Login Armor, mon plugin de sécurité WordPress, publié sur wpformation le 28 avril 2026. Le 29 avril paraît son article Login Armor WordPress : sécurisez vos accès efficacement. Vingt-quatre heures.
- OGEEAT, mon plugin SEO+GEO+E-E-A-T, publié le 14 avril. Le 15, son Optimiser votre visibilité avec le plugin OGEEAT. Vingt-quatre heures.
- Zero-click SEO, mon analyse de l’érosion du CTR à l’ère des AI Overviews, publié le 10 avril. Le même jour, son SEO zero click : adapter WordPress aux AI Overviews en 2026. Le. Même. Jour.
Ces écarts ne sont pas un hasard statistique. En vérifiant son profil, je constate qu’il me suit sur LinkedIn depuis avril 2026. Il reçoit donc une notification à chaque publication wpformation. La fenêtre 24 heures, c’est exactement le temps qu’il faut pour faire passer un article fraîchement notifié dans un LLM, le republier, le pousser sur Google.
La preuve verbatim, vérifiable sur Wayback Machine. Sur Login Armor, il reprend mes neuf modules dans le même ordre : "masquage de l’URL wp-login.php", "blocage de sous-réseaux IP /24", "authentification 2FA", "Administration avancée et gestion des urgences via WP-CLI", "notifications multi-canaux".
Sur OGEEAT, c’est ma nomenclature complète qui ressort : "score GEO unique en 12 points", "fichiers llms.txt et llms-full.txt", "Shadow Indexing", "AI Crawler Firewall", "schémas E-E-A-T". Tapez ces termes dans Google, vous tombez sur wpformation. Personne d’autre ne les utilise.
Sur Zero-click, mes quatre sources reprises dans le même ordre : SparkToro 58 %, Seer Interactive 61 %, Adobe sur le mobile, llmstxt.org pour la couche technique.
Son texte contient les marqueurs anti-IA stricts, lisibles à l’oeil nu pour qui forme à la rédaction. "Redoutable" trois fois en un seul article. "S’impose comme". "Stratégie de positionnement redoutable". "C’est une protection proactive indispensable". Toute formation rédactionnelle sérieuse apprend à éviter ces tournures… il les empile.
Le détail qui ferme le dossier : zéro lien sortant. Aucun lien vers Login Armor sur WordPress.org. Aucun vers OGEEAT. Aucun vers les études chiffrées qu’il cite. Aucun vers llmstxt.org dont il recommande pourtant l’implémentation. Tous ses liens pointent vers ses pages internes ou sa prise de rendez-vous.
J’ai publié un post LinkedIn nominatif le 10 mai 2026 documentant les trois cas. Jeremy m’a contacté en privé via mon formulaire de contact (le comble) pour reconnaître la pratique et s’engager à retirer les articles. Il ne s’est pas exprimé publiquement. Cette asymétrie n’est pas anodine : reconnaître en privé limite la casse réputationnelle, ne rien dire publiquement laisse la porte ouverte à recommencer ailleurs. C’est précisément ce qui rend la documentation publique nécessaire… sans elle, le coût social de la pratique reste nul.
Les versions originales sont archivées sur Wayback Machine, à toutes fins utiles : SEO zero click, Login Armor WordPress, plugin OGEEAT.
La chaîne industrielle : BRANDECLIC
Si Jeremy était un cas isolé qui se règle entre adultes, je n’écrirais pas cet article. Mais il y a Brandeclic. Et là, c’est une autre échelle. Bref.
Brandeclic.com se présente comme une "agence webdesign Suisse et France". J’ai découvert le site par les logs d’accès de mon serveur, en remontant la trace d’un hotlinking (fait pour un site tiers de servir une image directement depuis votre serveur, sans la copier chez lui). Une vérification rapide en a sorti un, puis dix, puis trente. J’ai arrêté de compter à 50 et lancé un audit complet du sitemap.
Les chiffres bruts de cet audit, daté du 10 mai 2026
- 143 articles publiés au sitemap, dont 128 sur WordPress, soit 89 % de la production.
- 70 correspondances probables avec mes propres articles, dont 30 reproductions vérifiées en profondeur.
- 110 articles publiés ou modifiés sur le seul mois de janvier 2026, soit 3,5 articles techniques par jour. Pas un humain. Personne ne tient ce rythme sur du WordPress, période.
- 23 articles sur 30 (77 %) intègrent des références images directes vers mon serveur. Mon hébergement finance le leur.
Trois signatures convergentes d’automation, indiscutables. Une signature. Mathématique. Indiscutable.
- Premièrement, le nommage des images. Sur les trois articles que j’ai disséqués, les fichiers s’appellent
tmpqx6lal6n.jpg,tmpfshkw_yh.jpg,tmp2m5jfqr_.jpg. Le préfixe "tmp" suivi d’un hash aléatoire est la signature universelle de la fonction Pythontempfileou de la commandemktempen bash. Aucun éditeur humain ne nomme ses illustrations comme ça. Ce sont des fichiers temporaires que le script de génération a uploadés tels quels. - Deuxièmement, la variance. Sur 45 articles testés au hasard, le nombre d’images par article est strictement constant. Une régularité parfaite ne peut résulter que d’un template figé.
- Troisièmement, les dates. Sur 100 % des articles, les dates de publication sont masquées. Aucune date n’est affichée nulle part, ni dans le corps de l’article ni dans les sections d’archives. Les seules dates accessibles sont celles que Google nécessite pour crawler. Cette dissimulation a un objet : empêcher la démonstration de la postériorité par rapport aux sources plagiées. La mauvaise foi est ici un fait technique mesurable…
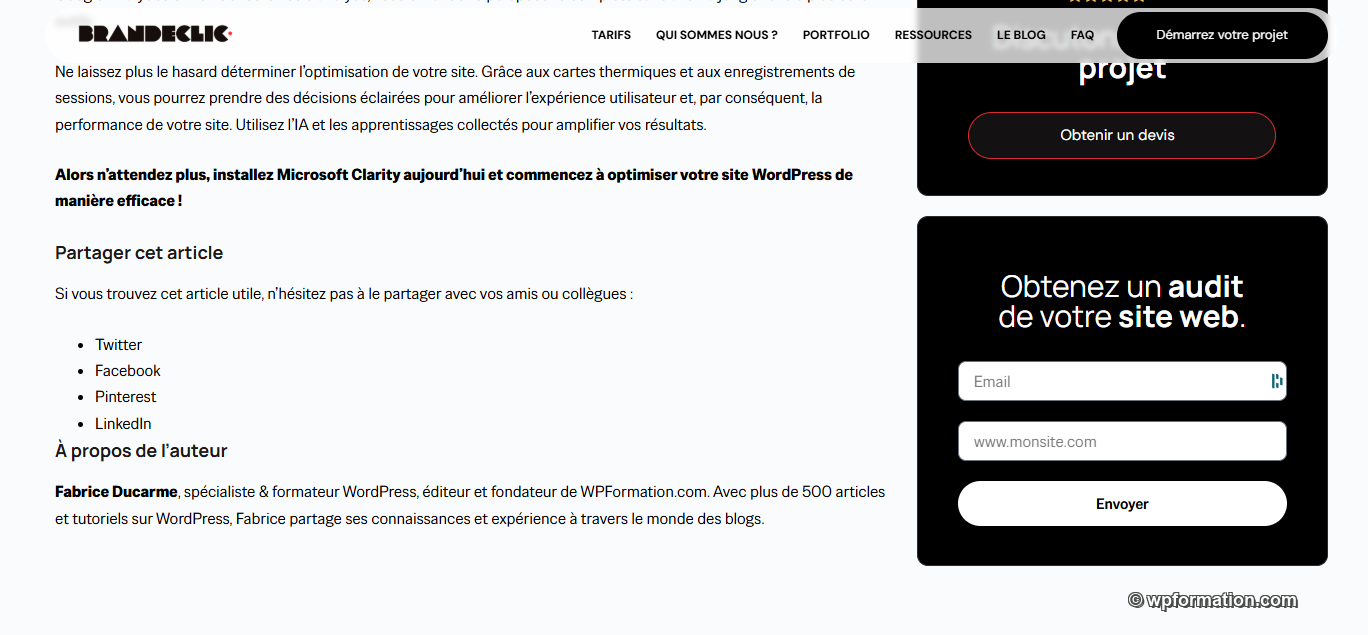
Le détail qui les enterre. Sur leur article Microsoft Clarity, en bas de page, on lit textuellement : "Fabrice Ducarme, spécialiste & formateur WordPress, éditeur et fondateur de WPFormation.com depuis 2009". Le LLM a oublié de retirer mon bloc auteur en réécrivant. Et a halluciné une date par-dessus le marché : wpformation, c’est 2012, pas 2009. La preuve est double. Aucun humain n’a relu, ET le LLM hallucine en plus de copier.
Encore plus fort. Un de leurs articles s’appelle littéralement "Devenir rédacteur indépendant sur WPFormation : guide complet". Ils ont mis le nom de mon site dans leur slug. Sciemment. Pas besoin de chercher loin pour la connaissance de la source : elle est gravée dans leur URL.
L’opacité juridique du site complète le tableau. Aucune mention légale identifiable. Aucun nom d’éditeur, aucune adresse, aucun directeur de publication. Le WHOIS pointe Hostinger Operations UAB en Lituanie, l’IP est française (213.130.145.181), la page "Qui sommes-nous" parle d’une "équipe de talents jeunes et dynamiques" sans aucun nom ni photo individuelle. Les témoignages clients sont signés d’un prénom et d’une initiale, et un même témoignage apparaît deux fois en page d’accueil avec deux orthographes différentes du nom de l’entreprise cliente : "Worldtraining" puis "World Training". Ça pue le LLM mal supervisé à plein nez.
Et un détail SEO industriel : le site dispose de pages-villes générées en série, sur le pattern d’URL /websites/agence-web-design-a-[ville]. Pour ranker sur "agence web Lyon", "agence web Bordeaux", "agence web Lille" en masse. Quid de la valeur ajoutée par ville ? Aucune.
Trois articles archivés sur Wayback Machine en exemples représentatifs : Microsoft Clarity, WPS Limit Login, WP Umbrella.
Mise à jour du 12 mai 2026. brandeclic.com a été suspendu par Hostinger 36 heures après ma notification LCEN. Le récit complet de la procédure et le modèle de mail anonymisé à recopier sont dans l’épilogue détaillé en fin d’article.
Comment se défendre quand on est victime ?
Pas de panique. Si vous publiez du contenu original sur WordPress et que vous voulez vous protéger contre ce type de pratique, voici la grille pratique. Quatre étapes, dans l’ordre. Il faudra détecter. Il faudra tracer. Il faudra agir techniquement. Et il faudra documenter publiquement.
1. Détecter
Comment savoir si on est victime ? Quatre signaux à surveiller en parallèle.
- Recherche d’image inversée sur Yandex (souvent meilleur que Google sur ce terrain) ou TinEye, à passer ponctuellement sur vos images les plus distinctives : captures de plugins, schémas, photos personnelles. Les fermes de contenu copient massivement les images, c’est moins cher que d’en générer.
- Google Alerts sur les termes que vous avez vous-même créés. Pour OGEEAT je suis alerté à chaque mention de "score GEO 12 points" ou "AI Crawler Firewall". Si quelqu’un d’autre s’en sert, je le sais dans la journée. Le pendant offensif, c’est de tester soi-même la citabilité de son site par les IA.
- Monitoring de marque via Brand24, Mention, ou simplement une Google Alert sur votre domaine et vos noms de produits.
- Surveillance des logs serveur. Un script qui repère les requêtes Referer venant de domaines tiers sur vos images. C’est exactement comme ça que j’ai découvert Brandeclic. Le hotlinking se voit immédiatement dans les logs Apache ou Nginx, avant même que l’article ne ranke.
2. Tracer avant d’agir
La tentation est de réagir à chaud quand on découvre un cas. Mauvaise idée. Première étape : figer la preuve, parce que l’auteur peut dépublier ou modifier dès qu’il sent le vent tourner.
Avant tout autre geste, lancez la Wayback Machine sur l’URL litigieuse via web.archive.org/save. Trente secondes, page figée pour toujours. C’est le geste qui transforme une accusation en pièce à conviction.
- Captures pleine page horodatées, depuis Chrome F12 puis "Capture full size screenshot".
- Sauvegarde du HTML brut. View Source, Ctrl+A, Ctrl+C, fichier .html daté. C’est la preuve technique du hotlinking et de la structure de liens.
- Archive de votre propre article sur Wayback Machine, à la date la plus proche de votre publication. C’est ce qui figera votre antériorité face à un copieur futur.
3. Agir techniquement
Pour le hotlinking, c’est immédiat. Quelques lignes dans votre .htaccess Apache (ou règle équivalente Nginx) qui détectent les Referer externes et servent une image de remplacement. Le résultat : l’article du voleur affiche désormais à ses propres visiteurs un visuel "ARTICLE PLAGIÉ. Source : votre-site.com".
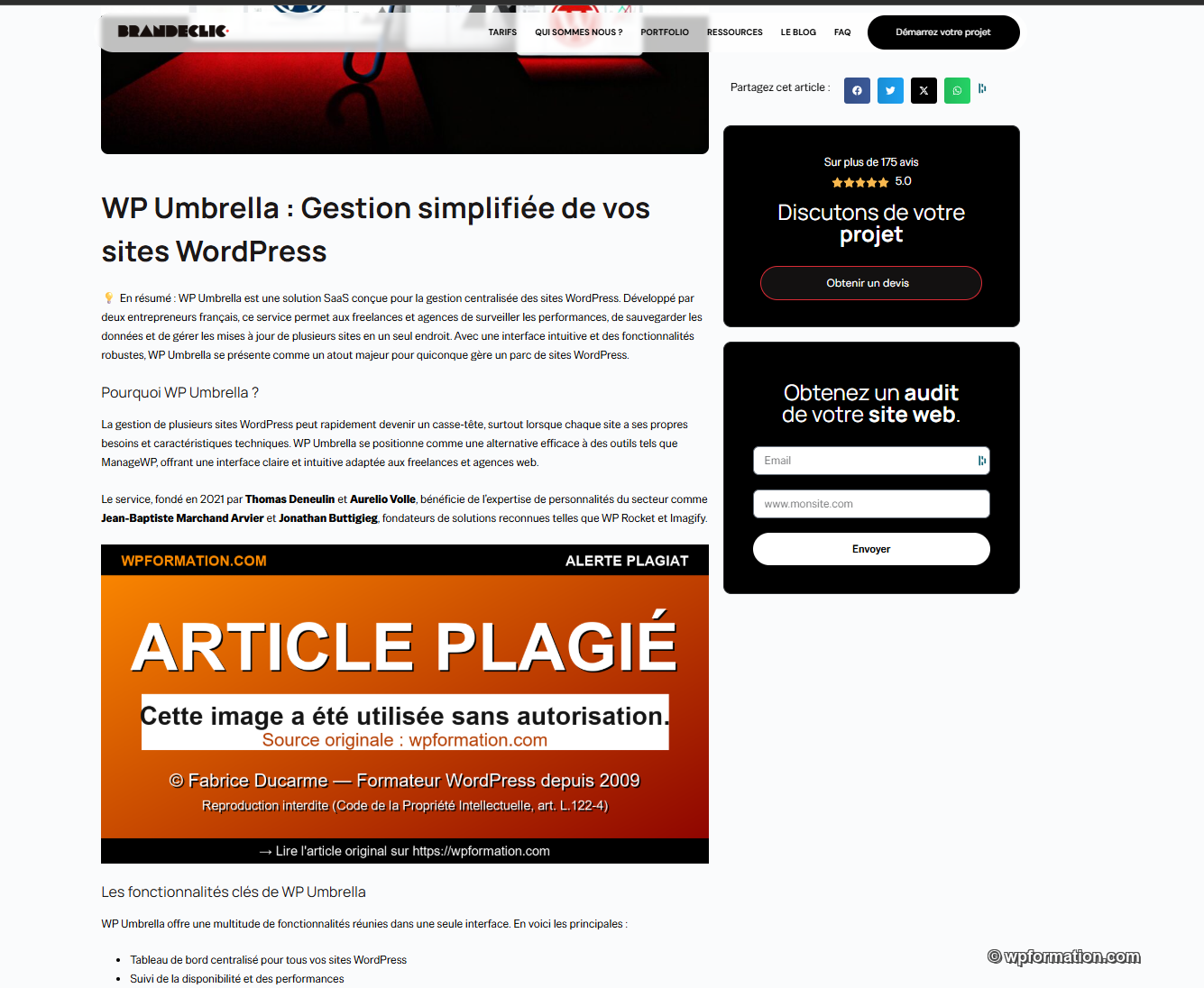
Automatique. Élégant. Irréversible sans qu’ils retravaillent chaque article un par un. Voilà ce que voient leurs propres visiteurs quand ils tombent sur un article pillé.
C’est exactement la mesure que j’ai déployée le 10 mai 2026 sur wpformation. Trois couches superposées, sans entrer ici dans le détail opérationnel (ce serait fournir le manuel d’évasion aux copieurs) : .htaccess qui filtre les Referer hostiles vers une image accusatrice, watermark dynamique conditionnel par User-Agent qui marque les images servies aux scrapers serveurs sans toucher aux visiteurs légitimes, et canary HTML invisible dans le contenu qui sert de preuve d’antériorité juridique. Le tout testé sur 11 scénarios avant rollout.
Pour la reprise structurelle sans hotlinking, c’est plus délicat. La structure d’argumentation et les choix éditoriaux ne sont pas protégés par le droit d’auteur français en tant que tels. Seule la forme l’est. On bascule alors sur du parasitisme commercial, qui se plaide mais demande du temps.
4. Documenter publiquement
C’est ce que je fais avec cet article. Quand un cas est documenté, archivé et indexé sur Google, il devient une dette de réputation qui se paie sur des années. Pour un freelance identifié, ça compte : ses prochains clients tapent son nom dans Google. Pour une ferme de contenu opaque comme Brandeclic, ça compte aussi : leurs prochains prospects font la même recherche.
Les excuses privées ne suffisent pas. Tant que le coût public reste nul, la pratique se généralise. C’est aussi simple que ça.
Pourquoi documenter publiquement plutôt que d’aller en justice ? Parce que la voie judiciaire est lente (12 à 24 mois pour une décision), coûteuse (3 000 à 8 000 € de frais de procédure pour un cas type), et souvent décevante (les dommages-intérêts couvrent rarement la perte de trafic réelle). La documentation publique indexée, elle, agit dans la semaine et coûte zéro. Les deux ne sont pas exclusives : on peut documenter en parallèle d’une procédure. Mais on commence toujours par documenter.
Le cadre juridique en 4 articles à connaître avant toute notification.
- Article L.122-4 CPI : la reproduction non autorisée constitue une contrefaçon.
- Article 6-III de la LCEN : tout site éditeur doit publier des mentions légales identifiables. Un site qui n’en a pas est en infraction directe, ce qui justifie la notification à l’hébergeur sans passer par l’éditeur masqué.
- Règlement européen DSA : tout hébergeur en Union européenne (cas d’Hostinger en Lituanie) est tenu de retirer un contenu sous 24 à 48 heures sur notification motivée.
- Article L.335-2 CPI : la peine est aggravée en cas de contrefaçon répétée. Trois ans de prison, 300 000 € d’amende. Un dossier à 30 articles documentés entre objectivement dans ce cadre.
L’IA est un exosquelette intellectuel, pas un copieur. Elle augmente la capacité de l’auteur. Elle ne le remplace pas.
Paula DuBonSens
Épilogue : le mail LCEN qui a fait suspendre brandeclic en 36 heures
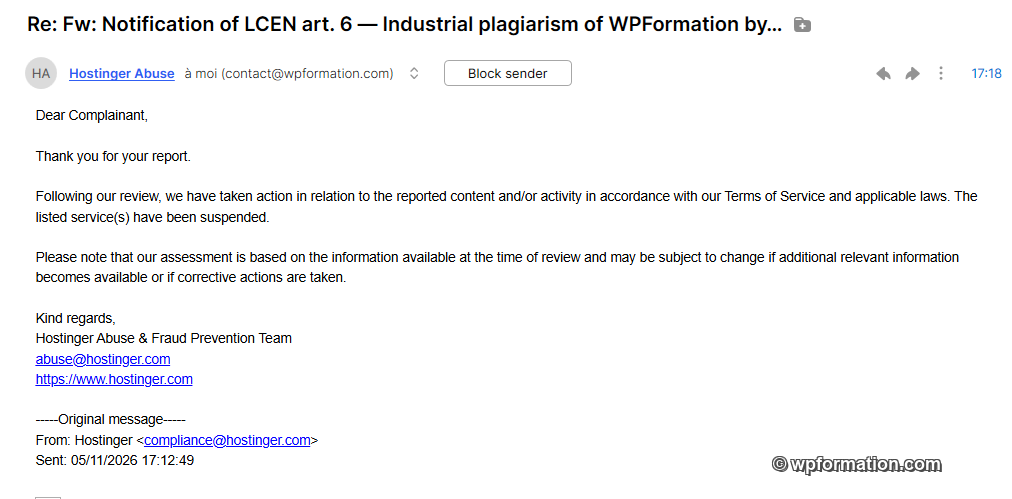
Mise à jour du 12 mai 2026. Le 10 mai 2026 à 5h41, j’envoie à compliance@hostinger.com une notification de contenu manifestement illicite au sens de l’article 6-I-5 de la LCEN et de l’article 16 du Digital Services Act, avec en pièce jointe le rapport d’audit chiffré : 70 articles plagiés, 102 hotlinks vers les uploads WPFormation, 315 fichiers tmp[hash] qui trahissent un pipeline Python tempfile.NamedTemporaryFile().
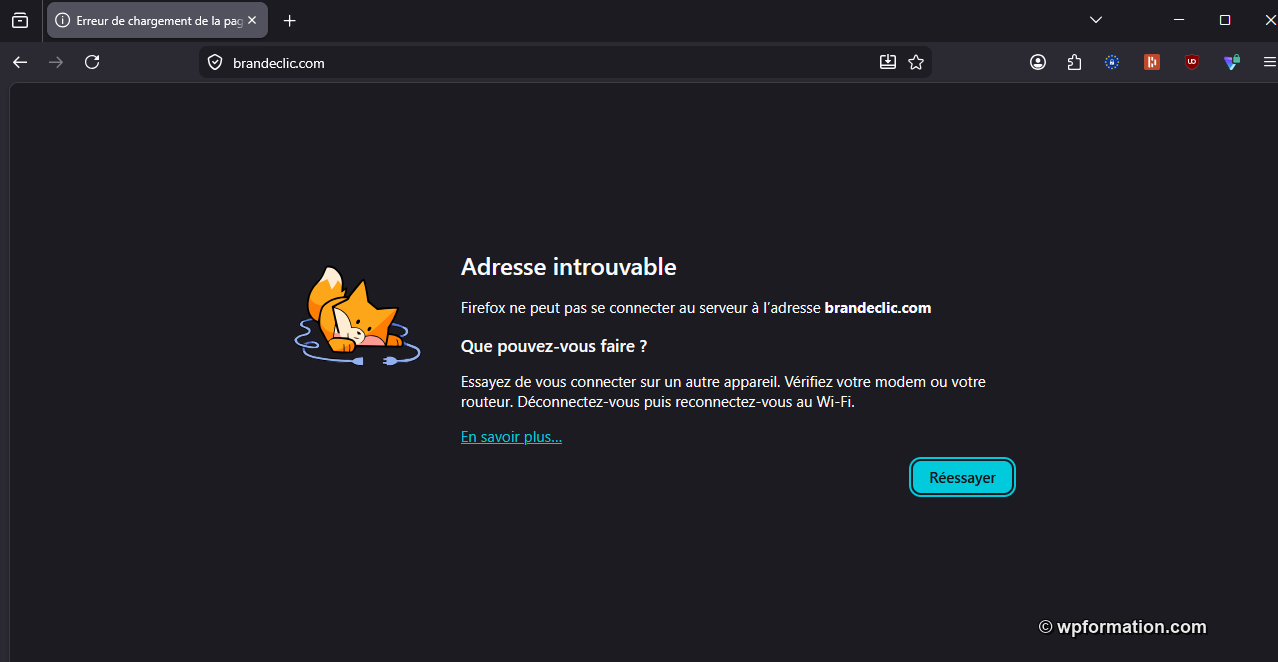
Le 11 mai 2026 à 17h18, Hostinger Abuse répond en six lignes : "The listed service(s) have been suspended". Le 12 mai au matin, brandeclic.com ne résout plus dans le DNS. Le domaine est éteint. 36 heures entre la notification et l’extinction, exactement dans le délai prévu par la LCEN pour un contenu manifestement illicite.
Pourquoi viser l’hébergeur plutôt que l’éditeur du site plagiaire ? Parce que brandeclic ne publiait aucune mention légale, en violation directe de l’article 6.III de la LCEN. Cible légalement inatteignable, mise en demeure directe impossible. La LCEN article 6-I-5 et le DSA article 16 ouvrent alors une voie plus efficace : la responsabilité civile et pénale de l’hébergeur s’engage dès qu’il a connaissance manifeste du caractère illicite des contenus et qu’il n’agit pas promptement. C’est cette responsabilité qui transforme un service abuse en service réactif sous 48 heures.
Le squelette à 10 blocs (à recopier, à adapter)
Voici le mail anonymisé que j’ai envoyé. Repliez-le, copiez-le, remplacez les crochets par vos informations et vos données d’audit. Ce squelette n’est pas du théâtre : chaque section a une fonction juridique précise qui neutralise une objection standard du service abuse. Le détail bloc par bloc juste après.
Modèle complet de notification LCEN (cliquer pour déplier)
NOTIFICATION DE CONTENU MANIFESTEMENT ILLICITE au sens de l'article 6-I-5 de la loi n° 2004-575 du 21 juin 2004 (LCEN) et de l'article 16 du règlement (UE) 2022/2065 (Digital Services Act) 1. IDENTIFICATION DU NOTIFIANT ------------------------------- Nom et prénom : [VOS NOM ET PRÉNOM] Activité : [VOTRE ACTIVITÉ ÉDITORIALE] Adresse : [VOTRE ADRESSE POSTALE COMPLÈTE] Email de contact : [VOTRE EMAIL] Téléphone : [VOTRE TÉLÉPHONE] Site éditorial : [URL DE VOTRE SITE] N° SIRET : [VOTRE SIRET] 2. IDENTIFICATION DU DESTINATAIRE ---------------------------------- [NOM DE L'HÉBERGEUR IDENTIFIÉ PAR WHOIS] Hébergeur du site [DOMAINE LITIGIEUX] (whois confirmé le [DATE]) [NUMÉRO AS, DATACENTER, PAYS] Le service abuse de [NOM DE L'HÉBERGEUR] est compétent pour traiter la présente notification en vertu du contrat d'hébergement liant [NOM DE L'HÉBERGEUR] à l'éditeur de [DOMAINE LITIGIEUX]. 3. IDENTIFICATION DU SITE LITIGIEUX ------------------------------------ URL : https://[DOMAINE LITIGIEUX] Hébergement : [NOM DE L'HÉBERGEUR] (votre infrastructure) Activité affichée : [ACTIVITÉ DÉCLARÉE PAR LE SITE] Particularité : le site ne comporte AUCUNE mention légale identifiable, en violation directe de l'article 6.III de la LCEN et de l'article L.111-1 du Code de la consommation. Aucun nom d'éditeur, aucune adresse, aucun numéro d'immatriculation, aucun directeur de la publication. Cette absence constitue en elle-même une infraction et empêche toute mise en demeure directe efficace, ce qui justifie le recours immédiat à l'hébergeur. 4. DESCRIPTION DES FAITS LITIGIEUX ----------------------------------- Le site [DOMAINE LITIGIEUX] publie depuis [DATE DE DÉBUT CONSTATÉE] une quantité significative d'articles qui constituent des reproductions non autorisées de contenus publiés sur [VOTRE SITE], dont je suis l'auteur et l'éditeur. Volumétrie objective (audit du [DATE D'AUDIT]) : - [N] articles publiés sur [DOMAINE LITIGIEUX] - [N] articles thématiquement alignés sur le sujet de [VOTRE SITE] - [N] articles présentant des reprises de fond confirmées (titre, sujet, structure, plugins traités) - [N] articles publiés ou modifiés en [PÉRIODE], soit une cadence de [N]/jour Indices d'industrialisation (à adapter à vos constats) : a) Pattern de nommage des images : signature [DÉCRIRE LA SIGNATURE TECHNIQUE OBSERVÉE], qui ne se produit jamais dans une production éditoriale humaine. b) Régularité parfaite : [DÉCRIRE LA RÉGULARITÉ STATISTIQUE OBSERVÉE] sur [N] articles testés au hasard. Cette régularité ne peut résulter que d'un pipeline automatisé. c) Masquage volontaire des dates de publication, en contradiction directe avec les pratiques éditoriales standard et avec l'obligation de transparence éditoriale, ayant manifestement pour objet d'empêcher la démonstration de l'antériorité des sources. Vol de bande passante : Sur les [N] articles audités en profondeur, [N] contiennent des hotlinks directs vers [URL DES UPLOADS DE VOTRE SITE], soit un total de [N] hotlinks identifiés. [DOMAINE LITIGIEUX] fait donc héberger une partie significative de ses ressources iconographiques sur le serveur d'hébergement payé par [VOUS] chez [VOTRE HÉBERGEUR], en violation des conditions générales d'utilisation de ce dernier. 5. ANTÉRIORITÉ DE VOTRE SITE (PROUVÉE) --------------------------------------- - Le site [VOTRE SITE] est exploité depuis [ANNÉE DE DÉBUT D'ACTIVITÉ ÉDITORIALE] (premier article publié : [DATE EXACTE]). - [N] articles sont publiés au total. - Chaque article comporte une URL canonique avec datePublished JSON-LD Schema.org Article (vérifiable par Schema Validator). - L'indexation Googlebot des articles est confirmée par Google Search Console depuis l'origine, datée et auditable sur demande. - [PIÈCE COMPLÉMENTAIRE ÉVENTUELLE : certification professionnelle, registre INPI, dépôt SACD, etc.] Échantillon de correspondances exactes (audit complet en pièce jointe) : [DOMAINE LITIGIEUX]/[URL ARTICLE PLAGIÉ] -> [VOTRE SITE]/[URL ARTICLE ORIGINAL] [Reproduire 3 à 5 correspondances minimum] 6. QUALIFICATION JURIDIQUE --------------------------- Les agissements de [DOMAINE LITIGIEUX] constituent des actes de : - Contrefaçon de droits d'auteur, par reproduction et adaptation non autorisée d'oeuvres de l'esprit originales (articles éditoriaux), sanctionnée par les articles L.122-4 et L.335-2 du Code de la propriété intellectuelle (peine maximale : 3 ans d'emprisonnement et 300 000 euros d'amende). - Parasitisme commercial, en récupérant le travail éditorial sans en supporter le coût, contraire à l'article 1240 du Code civil et à la jurisprudence constante en matière de concurrence déloyale. - Violation de l'article 6.III de la LCEN (absence de mentions légales). - Infraction à l'article L.111-1 du Code de la consommation (absence d'information du consommateur sur l'identité de l'éditeur). L'industrialisation de la production constitue une circonstance aggravante. 7. DEMANDE ---------- En application de l'article 6-I-2 de la LCEN et de l'article 16 du Digital Services Act, je demande à [NOM DE L'HÉBERGEUR] de : a) Procéder au retrait ou rendre inaccessibles les [N] articles [DOMAINE LITIGIEUX] listés dans l'audit complet ci-joint, dans un délai de quarante-huit (48) heures à compter de la réception de la présente notification. b) À défaut de coopération de l'éditeur de [DOMAINE LITIGIEUX] pour procéder à un retrait sélectif, suspendre l'hébergement de l'intégralité du site [DOMAINE LITIGIEUX], l'industrialisation de la contrefaçon empêchant tout traitement article par article praticable. c) Communiquer au notifiant l'identité civile de l'éditeur du site [DOMAINE LITIGIEUX] en application de l'article 6-II de la LCEN, aux fins de diligenter une procédure judiciaire. d) Conserver les éléments d'identification du titulaire du contrat d'hébergement et les logs d'accès en application de l'article 6-II de la LCEN, pour mise à disposition de l'autorité judiciaire. 8. DISPONIBILITÉ DU NOTIFIANT ------------------------------ Je me tiens à votre disposition pour : - Confirmer mon identité et la propriété du site [VOTRE SITE] - Communiquer le rapport d'audit technique complet - Toute pièce complémentaire utile à l'instruction de la présente notification. Je rappelle que, conformément à l'article 6-I-3 de la LCEN, votre responsabilité civile et pénale d'hébergeur peut être engagée si vous n'agissez pas promptement après avoir eu connaissance manifeste du caractère illicite des contenus signalés. 9. PIÈCES JOINTES ----------------- - audit-[DOMAINE LITIGIEUX]-[DATE].md (rapport d'audit technique complet) - captures d'écran des articles [DOMAINE LITIGIEUX] hotlinkant [VOTRE SITE] (à fournir si demandé par votre service) 10. ATTESTATION SUR L'HONNEUR (art. 6-I-5 LCEN) ------------------------------------------------ J'atteste sur l'honneur l'exactitude des faits décrits dans la présente notification et que je suis le titulaire des droits dont la violation est alléguée. Je suis informé que toute déclaration manifestement abusive ou erronée est sanctionnée par l'article 6-I-4 de la LCEN (un an d'emprisonnement et 15 000 euros d'amende). Fait à [VILLE], le [DATE] [VOTRE NOM] Éditeur - [VOTRE SITE] [VOTRE EMAIL] -- RÉFÉRENCES LÉGALES : - LCEN n° 2004-575 du 21 juin 2004, art. 6 - Code de la propriété intellectuelle, art. L.122-4 et L.335-2 - Code de la consommation, art. L.111-1 et L.121-17 - Code civil, art. 1240 - Règlement (UE) 2022/2065 (Digital Services Act), art. 16
1. Identifier le notifiant
Nom, prénom, adresse postale, SIRET, contact direct. La LCEN article 6-I-5 refuse les notifications anonymes : sans identification complète du notifiant, le service abuse classe le dossier sans même l’ouvrir. Le SIRET en particulier prouve que vous êtes une entité économique légitime, pas un troll. C’est aussi cette identification qui vous expose aux sanctions de l’article 6-I-4 en cas de notification abusive, et c’est précisément cette exposition qui rend votre notification crédible.
2. Identifier le destinataire (l’hébergeur, pas l’éditeur fantôme)
Whois du domaine litigieux pour viser l’hébergeur réel par son nom légal complet. Précisez le numéro d’AS, le datacenter, le pays. Cette précision démontre que vous savez à qui vous écrivez et empêche l’hébergeur de répondre "nous ne sommes pas concernés". Le mail va sur l’adresse abuse ou compliance officielle, jamais sur un formulaire de contact générique : les premiers font l’objet d’un suivi juridique, les seconds finissent en tickets support sans suite.
3. Identifier le site litigieux et son défaut de mentions légales
URL exacte, activité affichée, et surtout : relevez explicitement l’absence de mentions légales. C’est elle qui justifie de remonter directement à l’hébergeur plutôt que d’envoyer une mise en demeure à l’éditeur. L’article 6.III de la LCEN impose à tout éditeur la publication de mentions légales identifiables. Leur absence est une infraction autonome qui transforme votre notification en signalement multiple : contrefaçon plus défaut de transparence éditoriale, ce qui durcit le dossier pour l’hébergeur.
4. Décrire les faits avec des chiffres et des preuves d’industrialisation
Volumétrie chiffrée article par article, hotlinks, cadence quotidienne. Sans chiffres, l’hébergeur classe la plainte dans la catégorie "litige éditorial" et vous renvoie vers les tribunaux. Avec des chiffres, vous lui démontrez l’industrialisation, et l’industrialisation rend impossible le tri article par article. C’est précisément ce qui justifie une demande de suspension totale en alternative (point 7 du modèle). Si vous avez des signatures techniques (pattern de nommage automatisé, régularité statistique anormale, masquage des dates), citez-les nommément : ce sont des preuves matérielles, pas des opinions.
5. Prouver l’antériorité avec des éléments vérifiables
URL canoniques, datePublished JSON-LD Schema.org, indexation Google Search Console depuis l’origine, certificat professionnel ou registre INPI le cas échéant. Sans antériorité prouvée, l’hébergeur transfère le dossier au plagiaire pour "contestation", et le plagiaire prétend que c’est lui l’original. L’antériorité est le pivot du dossier : tout le reste s’effondre si vous ne pouvez pas démontrer que vous étiez là avant. Joignez 3 à 5 correspondances exactes article plagiat vers article original, ça suffit à matérialiser le pattern.
6. Qualifier juridiquement chaque infraction
C’est cette section qui transforme un "mail de plainte" en notification légale opposable. Citez les articles précis : contrefaçon (CPI L.122-4 et L.335-2, 3 ans plus 300 000 euros), parasitisme (Code civil article 1240), défaut de mentions légales (LCEN article 6.III), défaut d’information consommateur (Code de la consommation L.111-1). Une notification sans qualification juridique est juste un mail. Une notification qualifiée engage la responsabilité de l’hébergeur s’il l’ignore, et c’est exactement ce levier qui fait bouger le service compliance en quelques heures plutôt qu’en quelques mois.
7. Formuler une demande graduée et chiffrée
Trois demandes graduées : retrait sélectif sous 48 heures, ou suspension totale si le tri est impraticable, plus communication de l’identité civile de l’éditeur en application de l’article 6-II LCEN, plus conservation des logs. Toujours mentionner la suspension totale comme alternative : c’est souvent la solution la plus simple pour l’hébergeur quand l’industrialisation rend le tri article par article économiquement absurde. C’est ce qui s’est passé pour brandeclic : 143 articles à trier individuellement contre une suspension totale, l’arbitrage du service abuse est immédiat.
8. Affirmer votre disponibilité
Une ligne suffit : "Je me tiens à votre disposition pour fournir le rapport d’audit technique complet, des captures supplémentaires et toute pièce utile". Cette disponibilité désamorce l’objection standard du service abuse qui consiste à demander des compléments puis à classer faute de réponse rapide. En annonçant que vous êtes prêt à répondre dans la journée, vous lui retirez ce levier de procrastination.
9. Joindre les pièces matérielles
Rapport d’audit technique complet en pièce jointe (un fichier Markdown ou PDF), plus captures d’écran des articles plagiés et des hotlinks. Une notification sans pièce est systématiquement rejetée pour preuve insuffisante. Le rapport d’audit doit lister les URLs plagiat avec leur score de matching, les URLs originales correspondantes, le détail des hotlinks, et les signatures techniques d’industrialisation. C’est ce dossier qui transforme votre notification en dossier juridique "prêt à transmettre au procureur", formule qui force l’hébergeur à agir avant d’y être contraint.
10. Attester sur l’honneur
Mention obligatoire LCEN article 6-I-5 : sans cette attestation, la notification est irrecevable, point. Rappelez explicitement que vous êtes informé des sanctions de l’article 6-I-4 (un an d’emprisonnement et 15 000 euros d’amende en cas de notification manifestement abusive). Cette double mention prouve que vous savez ce que vous faites et que vous engagez votre responsabilité personnelle. C’est précisément cette responsabilité personnelle qui rend votre notification opposable.
Cette procédure engage votre responsabilité. La LCEN article 6-I-4 sanctionne d’un an d’emprisonnement et 15 000 euros d’amende toute notification manifestement abusive. Ne lancez une notification LCEN que si vous tenez vos preuves d’antériorité, votre rapport d’audit chiffré et votre qualification juridique. En cas de doute sur l’un des trois, un avocat en droit de la propriété intellectuelle vous coûtera moins cher qu’une condamnation pour dénonciation calomnieuse.
Si vous êtes victime de plagiat industrialisé et que l’audit technique vous dépasse (matching token-based, traque des hotlinks, identification de la signature de pipeline), j’accompagne ce type de dossier en consulting WordPress sur /expert-wordpress/, avec livraison du rapport d’audit et du modèle de notification adapté à votre cas.
Et la communauté WordPress dans tout ça ?
Je publie sur wpformation depuis 2012. Et j’ai intégré l’IA dans mes formations depuis deux ans. Ma position est constante. L’IA est un exosquelette intellectuel, pas un copieur.
Les cas Jeremy et Brandeclic sont exactement le contre-exemple à ne jamais reproduire. Ce n’est pas un usage de l’IA. C’est l’IA comme outil d’extraction de la valeur produite par d’autres, sans rien apporter en retour.
Mon conseil : si tu reprends le sujet d’un confrère, trois conditions, dans l’ordre.
- Tu cites la source en lien sortant. Toujours. Sans exception.
- Tu apportes une valeur additionnelle. Test propre, angle différent, public différent, donnée fraîche. Pas de réécriture LLM cosmétique.
- Tu acceptes que l’antériorité reste celle de l’auteur original sur les mots-clés qu’il a établis.
Sans ces trois conditions, ce que tu produis n’est pas du contenu. C’est de la dilution sémantique au service de ton SEO personnel, payée par le travail des autres.
Pour la communauté WordPress francophone, il devient urgent de rendre socialement coûteuse cette pratique. Pas par la judiciarisation systématique, lente et décevante. Par la documentation publique, partagée, indexée. Quand un nom devient associé à ce type de modèle dans les résultats Google, le coût d’opportunité finit par dépasser le bénéfice.
Questions fréquentes
Comment savoir si mon article WordPress a été plagié par une IA ?
Quatre signaux à croiser. Une recherche d’image inversée sur Yandex ou TinEye sur vos illustrations distinctives. Une Google Alert sur les termes que vous avez créés (mots-clés inventés, nomenclature propre). Un monitoring de marque via Brand24 ou Mention. Et la surveillance des logs Apache/Nginx pour repérer les Referer venant de domaines tiers sur vos images. Un texte plagié assisté par IA contient aussi des marqueurs lexicaux typiques (mots surutilisés comme "redoutable", "s’impose comme") que tout formateur en rédaction reconnaît immédiatement.
Le hotlinking d’image est-il illégal en France ?
Le hotlinking direct (servir une image hébergée sur un autre site sans la copier) est qualifié de contrefaçon par l’article L.122-4 du Code de la propriété intellectuelle dès lors que l’image est protégée par le droit d’auteur. Il est aussi qualifié de parasitisme commercial sur la base de l’article 1240 du Code civil, parce qu’il fait peser le coût de bande passante sur la victime au profit du copieur. La protection technique côté serveur (.htaccess Apache, Nginx) est donc parfaitement légitime.
Que faire quand on découvre un site qui plagie nos articles WordPress ?
Quatre étapes dans cet ordre. Tracer : archiver chaque URL litigieuse sur Wayback Machine via web.archive.org/save, prendre des captures pleine page horodatées, sauvegarder le HTML brut. Agir techniquement : déployer la hotlink-protection .htaccess pour transformer leurs images en visuel "ARTICLE PLAGIÉ", retourner leur SEO contre eux. Notifier l’hébergeur en s’appuyant sur la LCEN article 6-III si le site n’a pas de mentions légales et sur le DSA pour les hébergeurs UE. Documenter publiquement par un article indexé qui crée une dette de réputation durable.
Comment l’IA peut-elle être utilisée éthiquement pour rédiger sur WordPress ?
L’IA est un exosquelette intellectuel quand elle augmente l’auteur, pas un copieur quand elle l’efface. Trois règles non négociables : citer en lien sortant chaque source reprise, apporter une valeur additionnelle (test propre, angle différent, donnée fraîche), accepter que l’antériorité reste celle de l’auteur original sur les mots-clés qu’il a établis. L’IA peut aider à structurer, à reformuler, à fact-checker, à traduire. Elle ne peut pas légitimement extraire la valeur intellectuelle d’un confrère pour la republier sous une autre signature.